研究室で学生が取り組んだ、
一つの問題をもとに、
「データモデリングとは何か」を
説明してみようと思います。
昔むかし、
空海・最澄の時代、いやもっと前から、
僧侶の社会、僧侶の人間関係がありました。
僧侶の人物名、生年や没年、その他の情報は、
その師弟関係といっしょになって、
寺院に残されています。
この連綿と続く師弟関係をあらわした図は、
「系図」と呼ばれます。
系図のイメージ図を作ってみました。
一つ一つの丸が、人物になると思ってください。
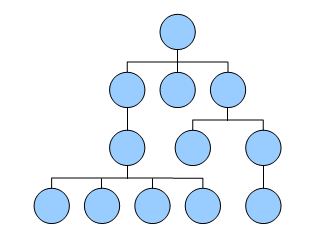
系図をコンピュータ上で見て、
師匠を順にたどっていったり、
親子や兄弟の関係と合わせて、複雑な人間関係を読み解いたり
するのは、国語学や仏教学の研究者の仕事です。
(コンピュータは何と言っても便利です。
見落としは、うんと少なくなくなりますし、
何千ページの情報でも、
ノートPCに入れて持ち運べますし。)
私たちの仕事は、
コンピュータで見ることのできる仕掛け作りです。
しかし、紙に書かれた活字の系図さえあれば、簡単に電子化できる、
というものでもありません。
コンピュータの上でデータを格納しておき、
あとで簡単に使えるようにするためには
どうすればいいか...。
コンピュータの前に座るのではなく、
机の上で、系図書をながめながら、
学生と先生とで、じっくり検討しました。
まず思い浮かぶのは、
「それぞれの僧侶は、0人以上の弟子を持つ」
という事実です。
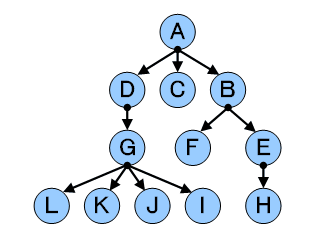
しかしこれは、
「データベース管理システム」と呼ばれる
数千、数万、いやもっと多いデータを
効率よく格納できるためのソフトウェアにとって、
あまりいいものではありません。
というのも、弟子が最大で何人いるか、
見当もつかないからです。
例えば、系図書をぱらぱらと眺めて、
一人の僧侶が30人の弟子を持っているから、
「それぞれの僧侶は、0人以上30人以下の弟子を持つ」
と言い切ることにしましょう。
この情報をもとに、
データベースを構築しようとするなら、
それはできます。
とはいえ、効率の面からは、問題があります。
標準的なデータベースでは、
格納する情報を、表形式であらわします。
先ほどの例を、表形式にすると...。
| 人物名 | 弟子1 | 弟子2 | 弟子3 | 弟子4 | ... | 弟子30 | 他の情報 |
|---|---|---|---|---|---|---|---|
| A | B | C | D | ... | ... | ||
| B | E | F | ... | ... | |||
| C | ... | ... | |||||
| D | G | ... | ... | ||||
| E | H | ... | ... | ||||
| F | ... | ... | |||||
| G | I | J | K | L | ... | ... | |
| H | ... | ... | |||||
| I | ... | ... | |||||
| J | ... | ... | |||||
| K | ... | ... | |||||
| L | ... | ... |
「何もないマス」、つまりムダが多いことに気づきます。
こんなムダを減らすことができないか、
師弟関係に立ち返って、考え直してみます。
そうして、
「それぞれの僧侶は、ちょうど一人、師匠を持つ」
ということに気づきました。
まさに、逆転の発想です。
(本当のところは、師匠が記録されていないことも
よくありますが、これは仕方がありません。)
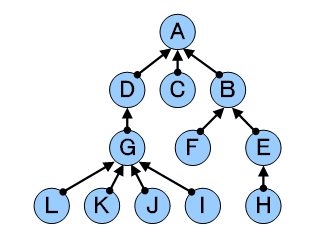
これで、効率よく表にすることができます。
マスの数が少ないということは、
コンピュータに乗せたとき、
ファイルサイズを小さくできるということです。
| 人物名 | 師匠 | 他の情報 |
|---|---|---|
| A | ... | |
| B | A | ... |
| C | A | ... |
| D | A | ... |
| E | B | ... |
| F | B | ... |
| G | D | ... |
| H | E | ... |
| I | G | ... |
| J | G | ... |
| K | G | ... |
| L | G | ... |
この表を見れば、例えば
「Gの師匠がだれか?」がすぐ分かります。
反対に、「Gの弟子がだれか?」というのも、
師匠がGになっている人を見つけるだけです。
データベースの分野では
SQLと呼ばれるプログラミング言語がよく使われます。
これを使って、
データベース管理システムに問い合わせれば、
弟子をすべて教えてくれます。
僧侶の数が何万人いても、
「インデックス」と呼ばれる特殊な情報をつけて、
データを管理しておけば、
問い合わせの時間は一瞬です。
ところで、
「0人以上の弟子」よりも「1人の師匠」の情報を
使うのがいいのは、
データベースに格納するという状況だから、
ということは、知っておいてください。
別の状況には、別の方法を使います。
例えば、Windowsのエクスプローラのように
系図を表示するプログラムを作るときには、
「0人以上の弟子」で考えないと、
うまく作れません。
ここまで見てきたように、
コンピュータで処理・検索・表示したい対象を、
そのコンピュータシステムに最も適した形にするには
どうすればいいか、
考え、悩み、ひらめいて、
何らかの書式で表現するまでの流れが、
「データモデリング」です。